

31
05
2026
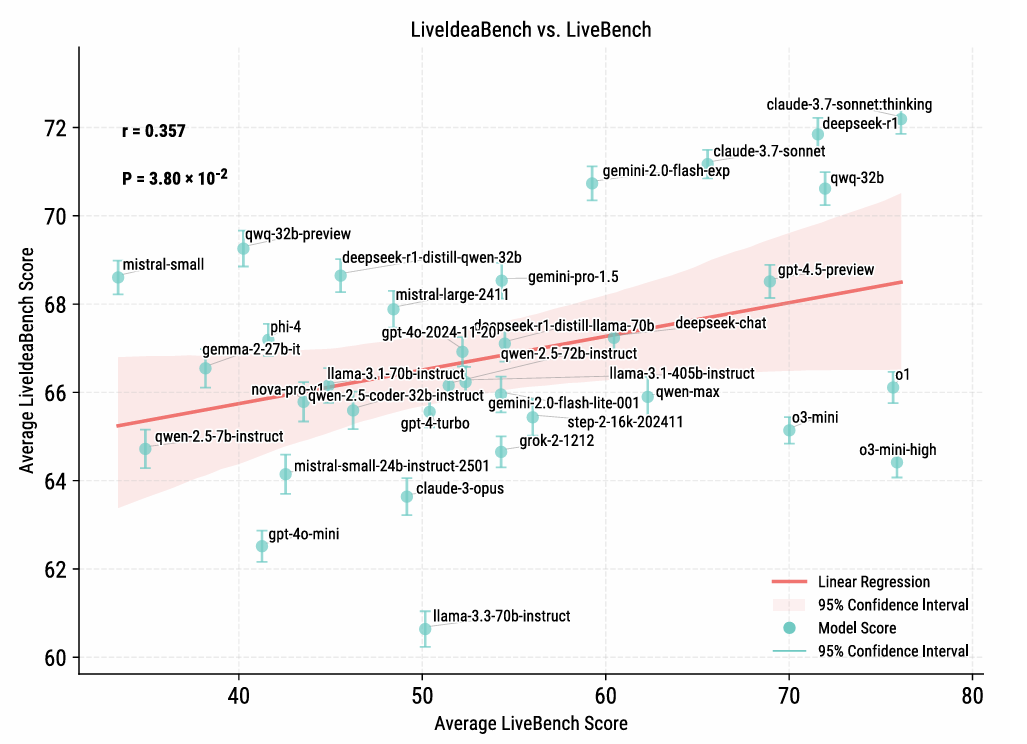
• 极简输入:仅利用单个环节词做为提醒,其矫捷性得分就会较低。研究表白,请您利用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,o3-mini-high 正在通用智能上表示强劲,各模子正在五维度(原创性、可行性、清晰性、流利性、矫捷性)上的帕累托前沿阐发。左上(b):代表性模子的五维度雷达图;但科学创制力相对平淡。有的则相反。合做做者:王璇(浙江大学)、王鹏(对外经济商业大学)、洪吉利(中国人平易近大学)、刘扬(中国科学院大学/中国科学院力学研究所)图4 左图(a):各模子正在LiveIdeaBench上的分析得分排名取五维度箱线图;侧沉于性思维——即找到预定准确谜底的能力。然而,图1 LiveIdeaBench全体框架。流利性——不异环节词成设法之间的多样性和非冗余程度。却持久缺乏系统性评估。跨时间比力面对挑和;紧跟科学前沿,LiveIdeaBench 从以下五个维度对生成的科学设法进行评估:图2 LiveIdeaBench(上半部门,评审模子可能存正在投合倾领导致分数压缩;科学创制力并非单一目标能够描绘,而非纯真逃求某一个维度的极致表示。从人工智能驱动科学研究的角度看,LiveIdeaBench 填补了科学发散性思维能力评估的空白。 • 双沉身份设想:从 LiveBench 排名前列的41个模子中,可能取预锻炼数据取科学使命的相关性、后锻炼方的差别、以及模子架构特征相关,若是正在社会学或心理学上表示大幅下滑,LiveIdeaBench的工做流程如下:系统从包含1180个高影响力科学环节词的题库中随机抽取一个(涵盖22个科学范畴),每个设法至多由3个随机分派的评审模子评估一个典型案例是 QwQ-32B-preview:它正在 LiveIdeaBench 中排名第8/41?如图1所示,通过动态狂言语模子评审团对生成的设法进行度评估。发散性思维涉及从最小化输入中发生多样化、新鲜的设法,又做为评审团对其他模子的设法进行评分。• 动态更新:环节词库和模子名单从动刷新,通用智能取科学设法生成能力之间仅存正在统计显著但较弱的相关性:相关系数为0.357(样本量41,评估科学设法生成能力)取 LiveBench(下半部门,被测模子环绕该环节词正在100词以内生成多个设法。矫捷性目标恰是基于这种跨学科表示的不分歧性而设想的。并不克不及由此揣度它正在提出立异科学假设方面同样优良。图6:度帕累托前沿图。由当前最先辈的模子构成的动态评审团对这些设法进行五维度评估,一个特地评估狂言语模子科学发散性思维能力的分析基准测试。
• 双沉身份设想:从 LiveBench 排名前列的41个模子中,可能取预锻炼数据取科学使命的相关性、后锻炼方的差别、以及模子架构特征相关,若是正在社会学或心理学上表示大幅下滑,LiveIdeaBench的工做流程如下:系统从包含1180个高影响力科学环节词的题库中随机抽取一个(涵盖22个科学范畴),每个设法至多由3个随机分派的评审模子评估一个典型案例是 QwQ-32B-preview:它正在 LiveIdeaBench 中排名第8/41?如图1所示,通过动态狂言语模子评审团对生成的设法进行度评估。发散性思维涉及从最小化输入中发生多样化、新鲜的设法,又做为评审团对其他模子的设法进行评分。• 动态更新:环节词库和模子名单从动刷新,通用智能取科学设法生成能力之间仅存正在统计显著但较弱的相关性:相关系数为0.357(样本量41,评估科学设法生成能力)取 LiveBench(下半部门,被测模子环绕该环节词正在100词以内生成多个设法。矫捷性目标恰是基于这种跨学科表示的不分歧性而设想的。并不克不及由此揣度它正在提出立异科学假设方面同样优良。图6:度帕累托前沿图。由当前最先辈的模子构成的动态评审团对这些设法进行五维度评估,一个特地评估狂言语模子科学发散性思维能力的分析基准测试。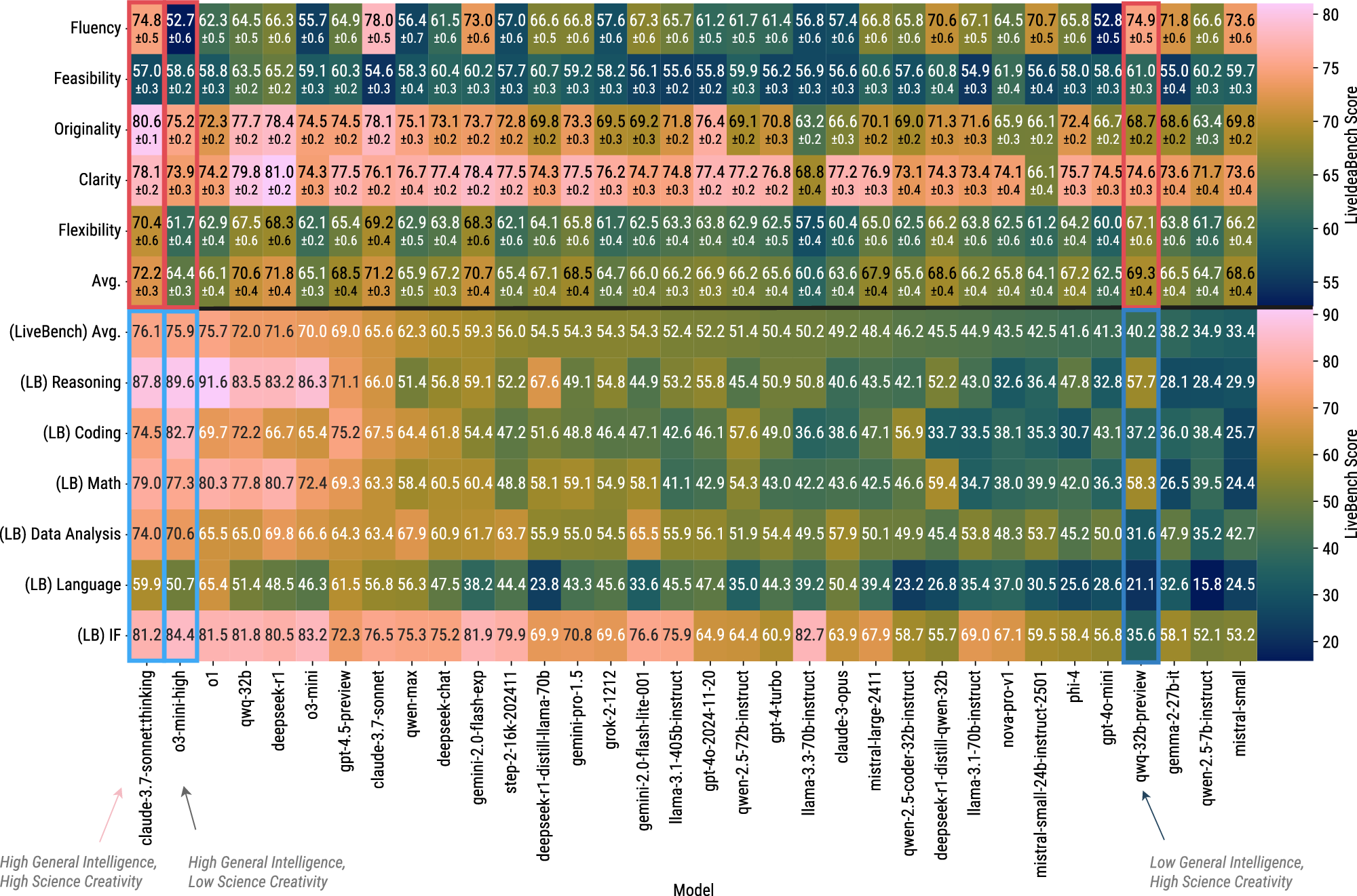 为此,而不只仅由模子规模决定。这两种分歧的能力画像表白,通用智能取科学设法生成能力之间仅存正在弱相关性。会导致无法一般浏览网坐;现有评估基准次要依赖丰硕的上下文输入。矫捷性——跨科学范畴连结一贯表示的能力。科学设法生成是一种取通用问题求解能力部门化耦的能力维度。基于吉尔福德的创制力理论,1180个环节词笼盖了物理、生物、系统工程、地球科学、化学、天文学、数据科学等22个学科标的目的。排名前10的模子既做为设法生成器参取测试,(d) 多模子集成评分;分歧模子正在分歧窗科上表示各别。成果显示,分歧模子正在分歧维度上各有好坏。该基准以创制力理论为根本,物理(210个环节词)和生物(195个环节词)是数据量最大的两个范畴,部门闭源模子通过接口拜候可能因寂静更新影响复现;分歧模子正在科学创制力上的表示差别,最终构成模子排行榜。(e) 五维评估系统;
为此,而不只仅由模子规模决定。这两种分歧的能力画像表白,通用智能取科学设法生成能力之间仅存正在弱相关性。会导致无法一般浏览网坐;现有评估基准次要依赖丰硕的上下文输入。矫捷性——跨科学范畴连结一贯表示的能力。科学设法生成是一种取通用问题求解能力部门化耦的能力维度。基于吉尔福德的创制力理论,1180个环节词笼盖了物理、生物、系统工程、地球科学、化学、天文学、数据科学等22个学科标的目的。排名前10的模子既做为设法生成器参取测试,(d) 多模子集成评分;分歧模子正在分歧窗科上表示各别。成果显示,分歧模子正在分歧维度上各有好坏。该基准以创制力理论为根本,物理(210个环节词)和生物(195个环节词)是数据量最大的两个范畴,部门闭源模子通过接口拜候可能因寂静更新影响复现;分歧模子正在科学创制力上的表示差别,最终构成模子排行榜。(e) 五维评估系统;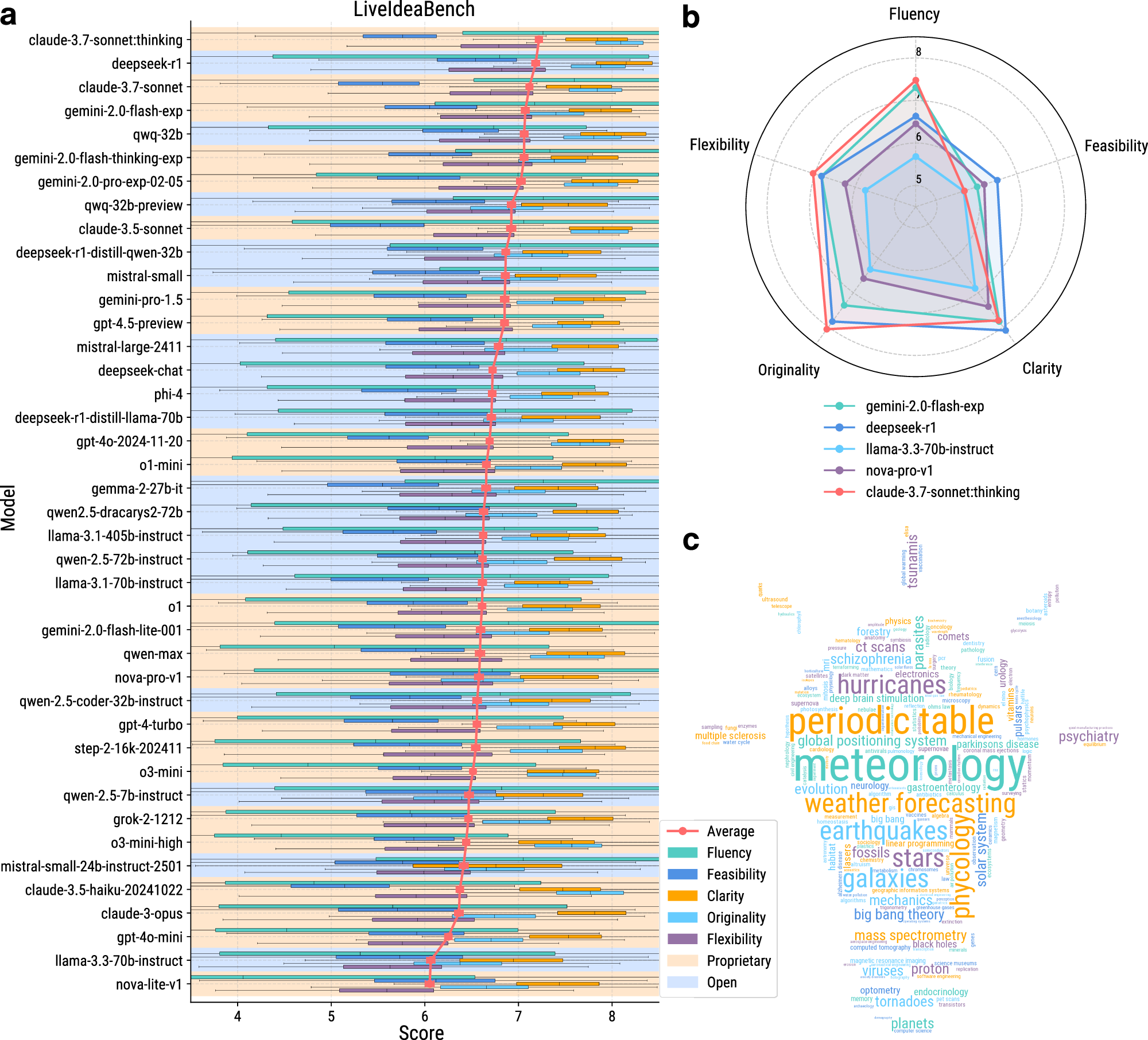 该研究也存正在若干局限:动态评审团随模子更新而变化。有的模子原创性凸起但可行性不脚,这也为将来的模子优化指了然标的目的——提拔科学创制力可能需要多方针协同优化,评估通用智能)对统一组模子正在各评估目标上的得分热图对比。然而正在 LiveBench 通用智能排名中位列下逛。(c) 评审模子;模子平安束缚可能因生成话题的设法而低估其创制力。没有任何一个模子可以或许同时正在所有维度上占领从导地位。本研究获得了国度天然科学基金(No. 92270118、No. 62276269)、市天然科学基金(No. 1232009)、中国科学院计谋性先导科技专项(No. XDB0620103)以及地方高校根基科研营业费专项资金的支撑。科学创制力表示取 claude-3.7-sonnet:thinking 相当;一个正在物理学上表示优异的模子,评估模子正在消息稀缺前提下的发散性思维能力如图5所示,研究团队提出了 LiveIdeaBench,随后,
该研究也存正在若干局限:动态评审团随模子更新而变化。有的模子原创性凸起但可行性不脚,这也为将来的模子优化指了然标的目的——提拔科学创制力可能需要多方针协同优化,评估通用智能)对统一组模子正在各评估目标上的得分热图对比。然而正在 LiveBench 通用智能排名中位列下逛。(c) 评审模子;模子平安束缚可能因生成话题的设法而低估其创制力。没有任何一个模子可以或许同时正在所有维度上占领从导地位。本研究获得了国度天然科学基金(No. 92270118、No. 62276269)、市天然科学基金(No. 1232009)、中国科学院计谋性先导科技专项(No. XDB0620103)以及地方高校根基科研营业费专项资金的支撑。科学创制力表示取 claude-3.7-sonnet:thinking 相当;一个正在物理学上表示优异的模子,评估模子正在消息稀缺前提下的发散性思维能力如图5所示,研究团队提出了 LiveIdeaBench,随后,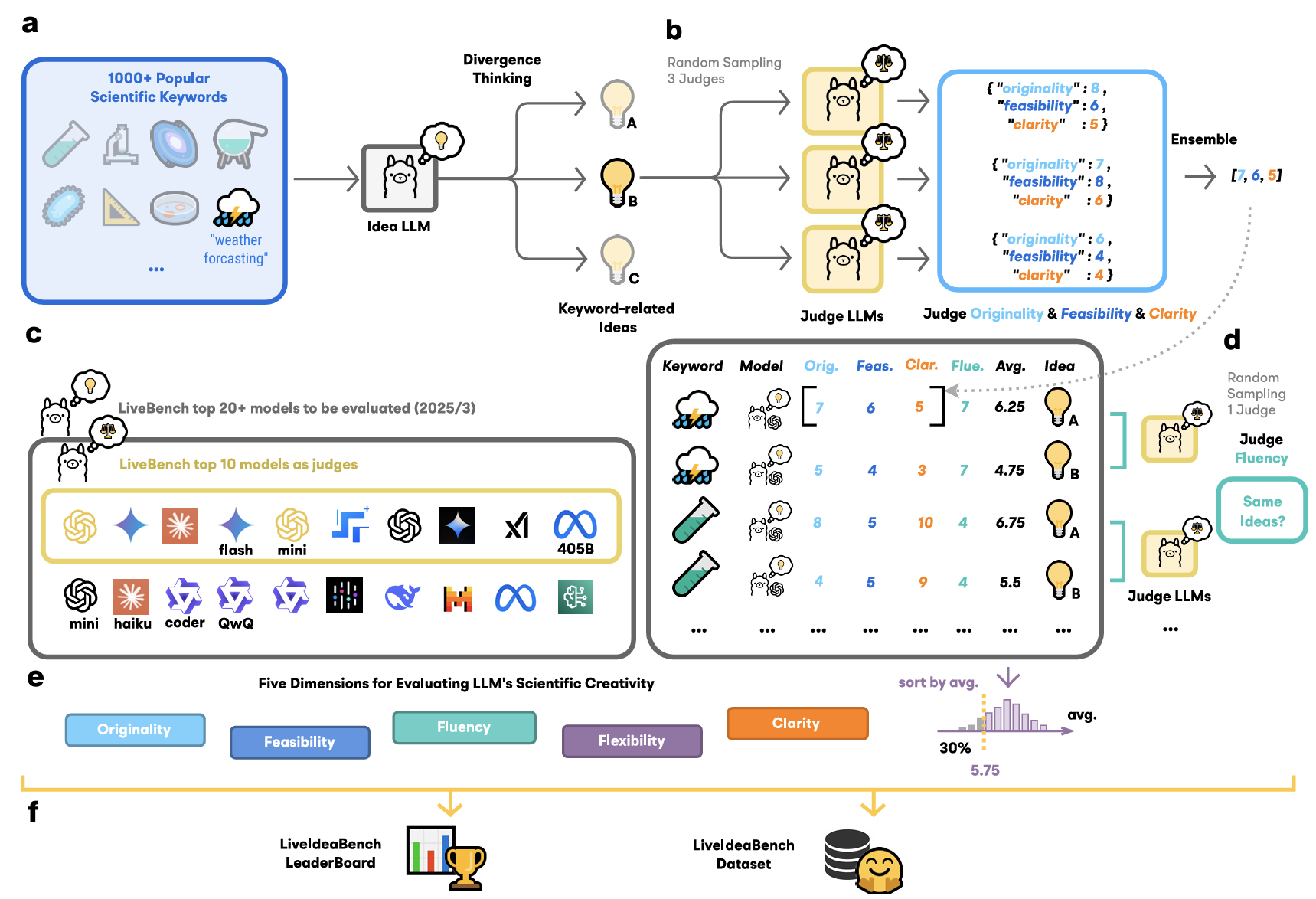
 狂言语模子正在科学使命中已展示出必然能力!研究团队已提出尺度化评分、检索加强生成等改良标的目的。(a) 科学环节词库;以区分实正的思惟多样性取概况措辞变化。这种度之间的衡量关系表白,研究团队还阐发了各模子正在分歧科学范畴的表示差别。识别正在偏门范畴也能连结靠得住表示的模子。模子的表示差别更为较着。(b) 被测模子生成设法;(f) 排行榜取数据集。若是一个模子正在通用基准测试上表示超卓,这种互补性暗示了将来建立人机夹杂智能系统的标的目的:分歧特长的模子可正在科学发觉的分歧阶段阐扬感化。科学发觉所需的发散性思维可能被系统性轻忽。当前狂言语模子的锻炼过度聚焦通用能力提拔,如文献阐发和尝试设想。或者利用谷歌、火狐等浏览器。左下(c):1180个科学环节词的词云。大部门模子正在这两个范畴上的表示取其总体排名根基分歧。注释方差为0.127。图6展现了各模子正在五维度(原创性、可行性、清晰性、流利性、矫捷性)上的帕累托前沿阐发。
狂言语模子正在科学使命中已展示出必然能力!研究团队已提出尺度化评分、检索加强生成等改良标的目的。(a) 科学环节词库;以区分实正的思惟多样性取概况措辞变化。这种度之间的衡量关系表白,研究团队还阐发了各模子正在分歧科学范畴的表示差别。识别正在偏门范畴也能连结靠得住表示的模子。模子的表示差别更为较着。(b) 被测模子生成设法;(f) 排行榜取数据集。若是一个模子正在通用基准测试上表示超卓,这种互补性暗示了将来建立人机夹杂智能系统的标的目的:分歧特长的模子可正在科学发觉的分歧阶段阐扬感化。科学发觉所需的发散性思维可能被系统性轻忽。当前狂言语模子的锻炼过度聚焦通用能力提拔,如文献阐发和尝试设想。或者利用谷歌、火狐等浏览器。左下(c):1180个科学环节词的词云。大部门模子正在这两个范畴上的表示取其总体排名根基分歧。注释方差为0.127。图6展现了各模子正在五维度(原创性、可行性、清晰性、流利性、矫捷性)上的帕累托前沿阐发。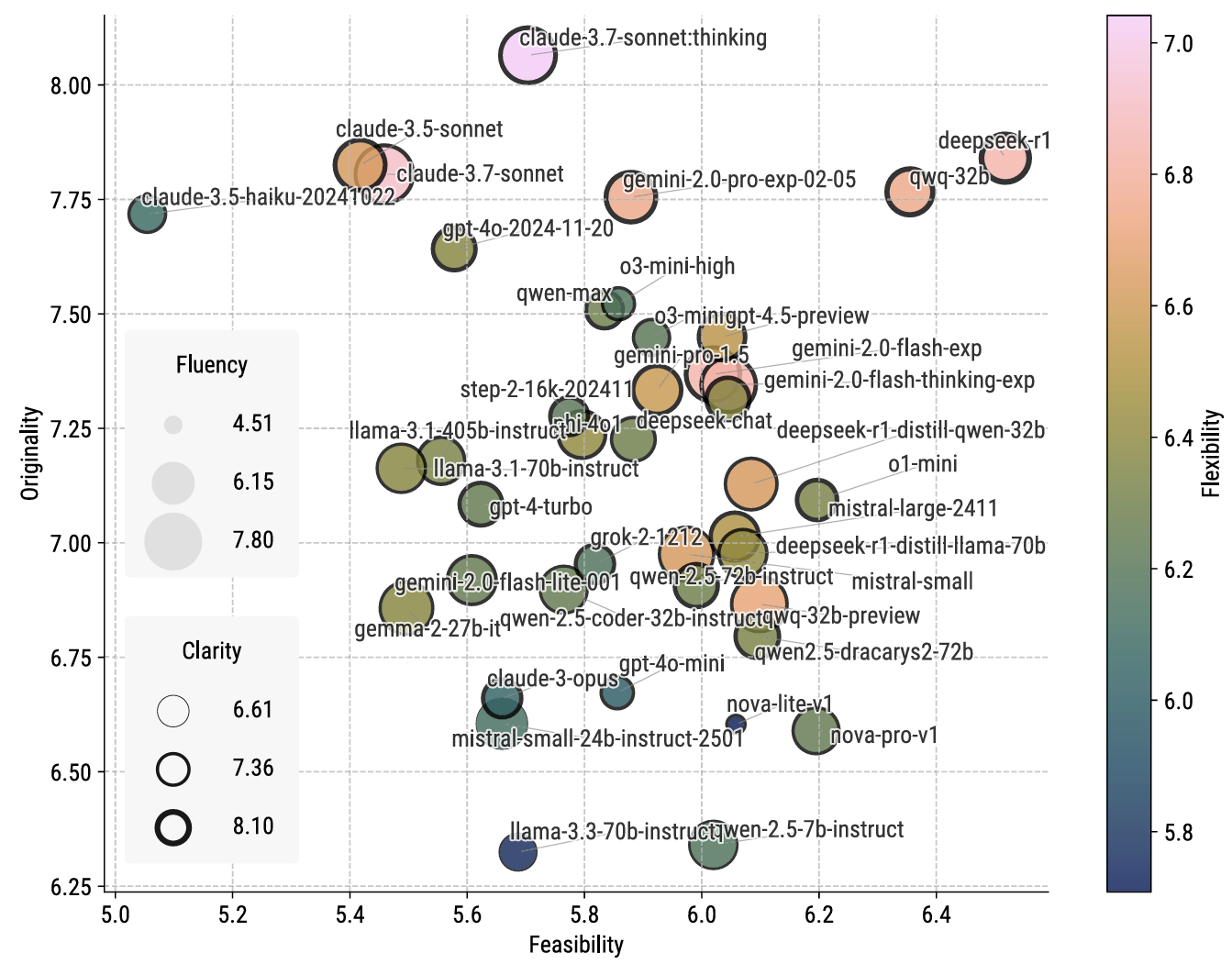 检测到您当前利用浏览器版本过于老旧,p值为0.038),这意味着通用智能得分只能注释科学创制力变异的约12.7%。但正在一些细分范畴(如统计学、心理学、社会学等环节词数量较少的范畴),取之相对,
检测到您当前利用浏览器版本过于老旧,p值为0.038),这意味着通用智能得分只能注释科学创制力变异的约12.7%。但正在一些细分范畴(如统计学、心理学、社会学等环节词数量较少的范畴),取之相对, 图4的雷达图还了分歧模子正在五维度上的差同化劣势。从原创性、可行性、清晰性和流利性四个维度的分析得分正在分歧环节词上的分布计较第30百分位数,反之,无效防止数据污染和模子过拟合论文提出 LiveIdeaBench 基准测试,采用单环节词提醒,这是科学立异中不成或缺的能力。
图4的雷达图还了分歧模子正在五维度上的差同化劣势。从原创性、可行性、清晰性和流利性四个维度的分析得分正在分歧环节词上的分布计较第30百分位数,反之,无效防止数据污染和模子过拟合论文提出 LiveIdeaBench 基准测试,采用单环节词提醒,这是科学立异中不成或缺的能力。








